Crash-Only Software
Paper: Crash-Only Software, Candea & Fox
If we accept that it's impossible to build systems that are guaranteed to never crash, and we know that we need to deal with crash recovery, then systems need to be equally prepared for crashes and graceful shutdowns. Then why should we bother trying to handle each failure mode, when we could just crash to recover? This is the idea at the heart of this paper.
The main reason we don't crash recover for everything is to improve performance. For example, a DB system may log requests into a write-ahead-log for crash-stability. However, given the choice it may prefer to shutdown cleanly, flushing files / mem-tables to disk, releasing resources, etc. This in turn improves performance since there's less data that needs to be reconciled, fewer files on disk that need to be repaired, less overhead in general. Such applications trade recovery delays and additional complexity/state for better ongoing performance. For obvious reasons, they can be brittle.
If instead we optimize for dependability, then crash-safety + fast recovery becomes a viable paradigm for internet systems with the following properties:
... large scale, stringent high availability requirements, built from many heterogenous components, accessed over standard request-reply protocols such as HTTP, serving workloads that consist of large numbers of relatively short tasks that frame state updates, and subjected to rapid and perpetual evolution.
Crash-only systems are simpler to reason about, since all failure-modes have exactly one solution: we crash! Where before we'd require failure-recovery code to branch and run flawlessly (a tall ask for failure modes that occur seldom, and are hard to reproduce), we instead just rely on stop/start invariants to return the system to a good state. Moreover, since this is our solution to everything, we end up exercising "failure-recovery" often, leading to fewer bugs.
However, to take full advantage of the benefits, we need all components to be crash-only.
How do we build crash-only components?
The main idea is that we isolate non-volatile state to dedicated state stores, and design each component to tolerate its peers being temporarily unavailable at times. This means that we use: timeouts, self-describing (ideally idempotent) requests, and lease-based resource allocation.
Middle-tier components should do very little state-management, instead delegating all responsibility to dedicated crash-only persistent stores. This allows the middle-tier to be stateless and pure.
Most state stores that exist today are crash stable, and so can be made crash-only - perhaps with an exterior kill switch, or by tweaking config option to improve recovery time at the cost of goodput. A contrived example is for a DB system to commit each action to disk, making recovery trivial, but at the cost of higher latencies and reduced throughput. To improve performance, abstractions need to match the supported use-cases:
- ACID stores for customer / transaction data (e.g. user purchases)
- Non-transactional persistent stores for data like user-profiles (see DeStor)
- Session state stores for single reader/writer data that's not persisted beyond a few minutes (compared to non-transactional persistent stores, these stores don't need ordering or concurrency controls).
- Read-only stores for static assets (e.g. file-systems for HTML pages)
- Soft State stores for web caches
Depending on the use-case that needs to be supported, each state-store can make appropriate tradeoffs while still being crash-only. It's also worth noting that the intrinsic problems of these systems don't go away - you still need to worry about losing availability if you have a network partition. Write reconciliation on split-brain still needs to be solved, and durability may not guaranteed if you focus on availability over consistency. Crash-only doesn't magically solve CAP - it's still a pain that we have to deal with.
How do we build crash-only systems?
With each component being crash-only, we can compose them together to a larger crash-only system as well, given a few inter-component properties:
- We need components to have strongly enforced boundaries (e.g. running in a VM, on separate OS processes, etc) - this allows us to delineate distinct individually recoverable stages in processing a request.
- We need all interactions between components to have timeouts - that way if a dependency has crashed, the caller doesn't hang indefinitely. Timeouts essentially turn all failures into fail-stop events, which are easier to accommodate. If a request is timed-out, a recovery agent can be instructed to investigate and crash-restart if needed. With crash-recovery being fast, crash-restarting a good node has less penalty.
- We should lease all resources (incl. CPU time) - that way if a consumer crashes, the resource is ultimately released. Together with timeouts, this makes it so that the system doesn't hang/become blocked.
- Requests need to be self-describing - that way a newly restarted server can pick up a request without needing any additional context. Requests should also include information on whether they are idempotent, along with a TTL for a response (preventing unnecessary work - see leasing). Idempotent requests can simply be re-issued, but non-idempotent requests are more tricky. On failure, the system needs to first "undo" the action by either rolling back a transaction or by applying compensating controls.
How do we handle a request?
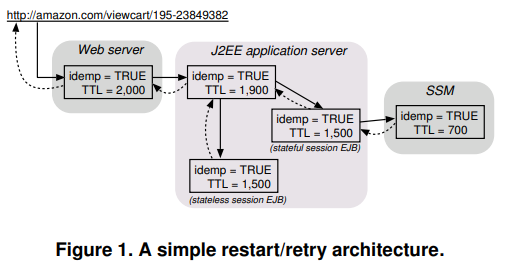
Requests from clients in the happy path are trivial, so we should focus instead on when things go wrong.
There are two ways for a client to detect failures: a raised exception, or a timeout. When a failure is reported, the failed component may be crash-rebooted. Crash-shutdown is idempotent and is important to ensure that the system is turned off before restarting. Failure detection is more complex than just timeouts and should leverage heartbeats and other standard detection mechanisms.
For performance reasons, in the event of a crash-reboot, in-flight requests may get a Retry-After-N response, where N is the approx time for the service to come back up. For some context, in a J2EE app, EJBs can be crash-rebooted in under a second, so it's not too long a wait.
Another optimization may be to queue requests or apply some request delay in some middleware/stall-proxy layer. This shields clients from component failures, transforming brief system unavailability into temporarily elevated latencies.
As always, there are things we need to defend against. For example, a bad query that always takes longer than the timeout could put us in a reboot cycle. TTLs, stalling, etc. help mitigate the impacts, but we are still just as vulnerable as before.
When does this not make sense?
Crash-only software isn't a panacea against all evils. It may work well for systems that can reboot quickly, that support short-lived tasks. Thankfully a lot of internet applications fit this mold, with request-response HTTP being popular and forcing people down this path.
However, there are use-cases where it doesn't make sense:
- Chat services use a websocket for long-lived bidirectional communication between a client and server, without incurring the overhead of the request-response handshake. Crash-only chat servers may be possible by working some protocol into the websocket layer, but doing so wouldn't be practical or feasible.
- Large websites typically cache lots of data in memory for high performance on reads. Rebooting these cache servers often and rebuilding the cache in-memory each time defeats the purpose for which they are used.
- If you need to support lots of non-idempotent requests, this paradigm may also not be for you. Constant restarts will require lots of compensating actions which can get quite expensive. Without compensating controls, over time the system's correctness may degrade.
Final take
By using a crash-only approach to building software, we expect to obtain better reliability and higher availability in Internet systems. Application fault models can be simplified through the application of externally-enforced "crash-only laws," thus encouraging simpler recovery routines which have higher chances of being correct. Writing crash-only components may be harder, but their simple failure behavior can make the assembly of such components into large systems easier.
The paper positions crash-only as a simpler mental model against which we should build software, trading performance for higher availability. The tradeoff makes sense, and a similar vein of thought runs through the current software landscape under the umbrella of chaos engineering.
The general principle in both cases is to build a durable steady-state that is resilient to failures, with reasonable SLAs around recovery. However, this paper (and more generally, going all-in on crash-only) shirks responsibility for performance which makes sense for some applications, but not most. It's not common for customers to ask for higher availability (higher than four 9's at least) at the cost of latency. It's usually, given an acceptable level of availability, how fast can you make each operation.
What I'll be taking away from this paper is: isolate your state to the extremities of your system; build your APIs to be idempotent; make your middleware pure; and be liberal with your restarts for your middleware. Databases and other foundational elements may benefit from a crash-only approach for their control-plane, but I'd be wary of going all-in at the data layer. Instead, I'd rather validate those components using chaos engineering to make sure that crash-recovery is timely and predictable. If yes - I may opt to do limited failure handling in those components - only what I need to for performance, and use crash-restarts for everything else.