The Case for Tiny Tasks in Compute Clusters
Paper: The Case for Tiny Tasks in Compute Clusters, Ousterhout et al.
Typical task-scheduling for data-parallel computations suffers from a host of issues including scheduling unfairness, stragglers, and data-skew. This paper explores reducing task-granularity as way to mitigate these issues. It asserts that with more engineering, the overhead of tiny-tasks is manageable. The paper is mostly theoretical - a thought exercise in how this could be made real.
Smaller tasks provide a host of benefits:
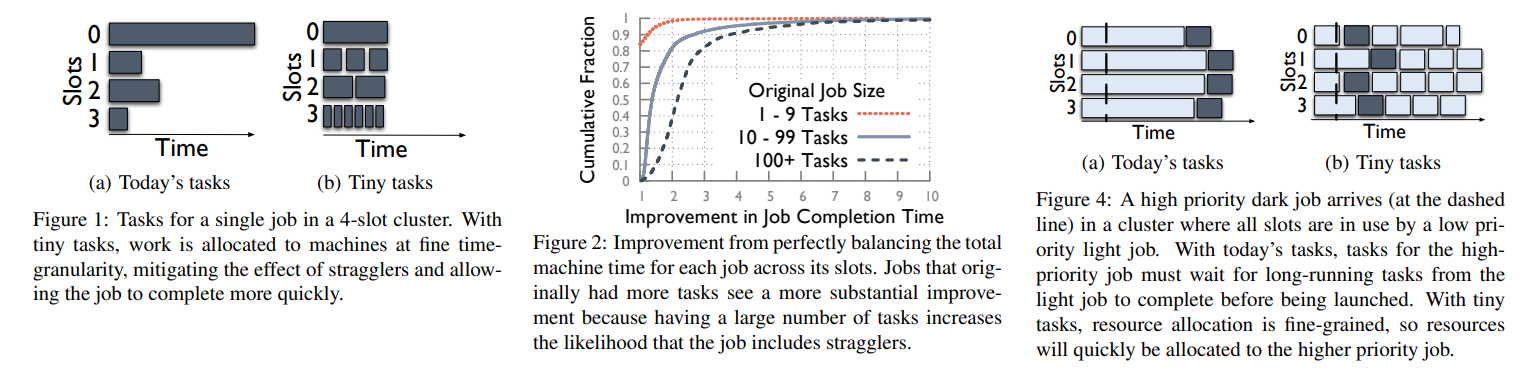
- Tiny tasks allow you to run mixed processing modes (batch and interactive), on a single framework. With larger tasks you don't have an upper-bound on how long it'll take to complete a task. This makes you allocate separate resources to handle interactive & batch loads. This in turn limits utilization since sometimes resources are going to be sitting around doing nothing, but in return you get responsiveness. With tiny tasks you wait 100ms for prior tasks to complete, and you end up getting good responsiveness. See Fig 4.
- Tiny tasks mitigate the effects of stragglers. Most processing takes time because of stragglers, extending job runtimes by up to 5x. With tiny tasks, we still have stragglers, but we schedule around them. The work is allocated at such fine granularity that slower processes just end up completing less tasks, with faster processes picking up slack. See Fig 1.
However, to get there we need: (a) a highly scalable scheduler that can make frequent scheduling decisions: >> 1M/s (b) task launches must have very little overhead (c) tiny-tasks read tiny amounts of data which means that we need a FS that's performant under many tiny writes/reads (d) we need some way of splitting everything into tiny-tasks.
Under this paradigm we could get improvements for median job-runtime of around 2.2x, and p95 job-runtime of around 5.2x for jobs that originally had > 100 tasks (Fig 2 - based on a 54K job trace from Facebook). We also get better resource-sharing between interactive and batch loads without sacrificing responsiveness too much.
How do we build systems to support tiny tasks?
While existing frameworks can benefit from the use of smaller tasks (as shown in Figure 3), supporting tiny tasks for all jobs in a large cluster requires addressing numerous challenges. A cluster supporting tiny tasks must provide low task launch overheads and use a highly scalable scheduler that can handle hundreds of thousands of scheduling decisions per second. Tiny tasks run on small blocks of data, and hence require a scalable file system. To ensure that tasks can complete quickly, we propose giving the framework more control over I/O. Finally, ensuring that all jobs can be broken into tiny tasks requires some improvements to the programming model; e.g., support for framework-managed temporary storage.
Concretely we need a cooperative execution model (where tasks explicitly release resources when done, as opposed to a pre-emptive model). Moreover, tasks in jobs need to be an atomic and idempotent unit of execution - safe to be retried, and capable of completing by themselves.
We also need a scalable storage system - the time needed to read input data is likely the limiting factor in driving down task durations. Previous research suggests that 8MB random disk-reads can achieve 88% of the throughput of sequential reads today. This suggests that tasks should work on 8MB chunks of data. Assuming a 100MB/s disk-read, we're looking at task-durations of around ~100ms. We also need support for small data-blocks. Flat Data Center Storage (FDS) might be a good choice here.
Low-latency scheduling is a must. Tasks take ~100ms, and then we need to allocate the next task. To do this we need information, and we need it fast: we can compress task descriptions, cache descriptions on the task worker, and use a decentralized approach like Sparrow. This allows us to scale >> 1M decisions/s.
The overhead for task-launches needs to be small. We can't spin up a JVM each time. Today Spark has dropped launches to 5ms, but we can do better. If we cache binaries, and all hosts are found within the same datacenter, the problem simplifies to making an RPC call for the task. This brings <50 micro-sec launches to the realm of possibility.
We also need an intelligent FS layer. As one task completes, we need the next set of data to be available in-memory, while tasks are ready - we should pipeline reading in the next set of data. This makes it so the scheduler needs to be holistic - aware of each stage of the computation.
Finally, we need to be able to break down all tasks to tiny tasks. This is mostly true today (e.g., reduce operations can be split down using map-side combiners or aggregation trees). However, tasks like count-distinct are a thorn. To solve these tasks, we need low-latency, massively parallel state storage. A few large tasks aren't too bad if the proportion of large tasks is low, they can run on the same infrastructure with negligible impact to the other (smaller) tasks.
Alternatives to tiny tasks
While there are alternatives, they're not as compelling.
- Pre-empting tasks solves the sharing problem since the system is more capable of tightly controlling the scheduling quanta. However, the cost to switch tasks can be severe, with intermediate data being several GBs. Fault-tolerance is also rough, since if a long-task fails it needs to be re-executed from the beginning. Tiny tasks don't quite have this problem.
- Static course-grained resource allocation also solves the sharing problem by allocating additional resources for interactive jobs. That way we don't suffer from head-of-line blocking by long-running tasks. However, resource-utilization isn't great with some of these resources not being under constant load. Omega (Google) solves this by sharing these static resources across multiple frameworks, each of which perform their own task scheduling. Despite this, tiny tasks with a holistic scheduling algorithm will drive even better utilization.
- Skew-detection and handling systems exist that work on task speculation and cloning. They handle task-runtime skew by modeling the causes for skew and accounting for these causes when scheduling tasks. While we see moderate improvements to task skew, they rely on a fragile set of signals that don't work in all cases.
Final take
There is no doubt in my mind that if there were no overhead, and we were able to scale to schedule holistically, tiny tasks would lead to significant performance improvements. But those are quite tall asks.
My bigger concern is around the security and task-isolation guarantees that can be provided for tiny-tasks. If we stick to framework primitives, we may be okay, but systems like Spark are popular because they provide ways for users to define custom functions. With a shared cluster that's running user-defined-functions, I wonder if a malicious actor could attempt to subvert controls gaining access to data that's not theirs. You could work around this by adding task isolation (e.g., using firecracker vm), but that usually comes at the cost of initial task-launch.
There's also the cost of coordination - if we're doing massive group-by operations, we may need to contend with significant data shuffling. This could be made worse if we break it down to many tiny tasks, especially when we have few workers (data locality with intelligent scheduling may no longer be possible). This can be mitigated by adding more workers, but that's not really viable for smaller companies/use-cases.
While the idea is intriguing, it seems like it's a paradigm that would be useful for the FAANG companies - services like AWS Firehose which basically do lots of tiny data transformations may benefit from the insights this paper has to offer. I do not think it's general-purpose advice for all ETL jobs.